Helpful or Harmful? How to Trust AI-Generated Summaries
October 15, 2025
·Layla Bitar

- You come across a new patient case.
- You open PubMed.
- You start searching using the right keywords and filters.
- You get thousands of papers.
- You skim a few abstracts, saving the ones that feel relevant, and discarding the rest.
- Then you block off time to read them thoroughly.
This process is tedious and eats up precious time.
It’s no controversy that published research is oversaturated. Clinicians and researchers are overwhelmed trying to figure out which papers are most relevant to their work.
In the era of large language models (LLMs), many have started relying on tools to speed this up. Think ChatGPT, Perplexity, and similar platforms.
But here’s the gap: generational differences.
For instance, older physicians prefer traditional methods. They trust the rigor of manual searches and are wary of AI shortcuts. On the other hand younger physicians and residents lean heavily on free-access AI tools. They are fast and efficient, but not validated for high-stakes healthcare.
So why does this gap exist? And how do we bridge it?
The truth is: both sides have valid concerns. After interacting with some physicians; these are their perspectives:
- Traditional physician: “This is how I’ve always done it. It’s robust. I don’t trust AI tools.”
- Modern physician: “Science evolves too fast. Without AI, I’ll never keep up.”
Each sees the other’s approach as flawed: one is too slow, the other too trusting.
Our aim is to close that gap. Yes, AI is remarkable at summarizing research papers, extracting main points, and tailoring information to queries. But it’s even more powerful if we learn how to evaluate when to trust an AI-generated summary and when not to.

How AI Summaries Work
Let’s say you want to chat with the latest papers on post-infection in stem cell transplantation. You type your query into ChatGPT.
Here’s what happens under the hood in a very high level overview:
- Your query is converted into a vector embedding: a numerical representation of its meaning.
- The LLM compares this embedding with its “concept space” (the embeddings it was trained on or whatever text it has access to).
- It retrieves the most relevant text chunks from research papers.
- It then generates a natural language response based on those chunks and outputs a summary.
Powerful? Yes.
But it is prudent to keep in mind that this is pattern recognition, not true understanding.
When AI Summaries are good
AI summaries can support research and clinical work in several complementary ways. They can condense long and complex text into clear takeaways such as the primary endpoint, population size, and outcomes, giving readers a head start before committing to the full text.
Building on this, AI has the potential to make literature more accessible to non-experts by translating technical jargon into plain language, which helps patients, policymakers, and allied health professionals understand the implications of new findings and engage more meaningfully with the science.

When AI Summaries Are Dangerous
AI summaries, while useful, can also carry significant risks if taken at face value. One of the most concerning issues is the risk of hallucinations, where the AI confidently presents information that doesn’t actually exist in the source text. Such as implying a drug improved survival when the study only measured symptom relief.
Even when the facts are technically correct, another danger arises from losing context or nuance. Research papers often include crucial limitations such as small sample sizes or methodological biases. When these are omitted, a “statistically significant but not clinically meaningful” finding might get flattened into a misleading claim of effectiveness.
Adding to this problem is the AI’s polished, authoritative tone. Which can give a false sense of reliability. A clinician pressed for time may unconsciously trust the summary more than it deserves, mistaking fluency for accuracy. In addition, AI can contribute to fragmentation of evidence by pulling snippets from multiple papers without clear attribution, making it difficult to know which claim came from which study.
Together, these risks make it clear that while AI can accelerate the reading process, unchecked reliance can compromise the very integrity of evidence-based practice.
How to Evaluate an AI Summary
This is where frameworks come in. A structured way of checking an AI-generated summary can prevent blind reliance.:
- Grounding: Does the summary tie back to the original source text? If a claim isn’t directly supported by the paper, it’s a red flag. Ask yourself: Can I point to the exact paragraph or figure where this is stated?
- Coverage: Does the summary include all the critical points including limitations, methodology, and context? A good summary captures both what was found and under what conditions it was found.
- Transparency: Does the AI tool provide citations, links, or reference markers? Can you trace every claim back to a verifiable source? If the output is a “black box,” be skeptical.
- Fit for Purpose: Not all tasks require the same level of accuracy. An AI summary might be perfect for giving a quick orientation before a journal club but absolutely inadequate for making a clinical decision. Always match the use case with the reliability needed.
- Human-in-the-loop check: The summary should never be the final word. Instead, treat it as a starting point for deeper analysis.
At Meddit, we’ve designed our system with this very challenge in mind. Our outputs are engineered to be citation-first in which every response is grounded directly in the source material.
When you ask a question, our tool doesn’t just generate text out of thin air; it actively searches trusted databases like PubMed or clinical trial registries, retrieves the relevant abstracts, and distills the main points.
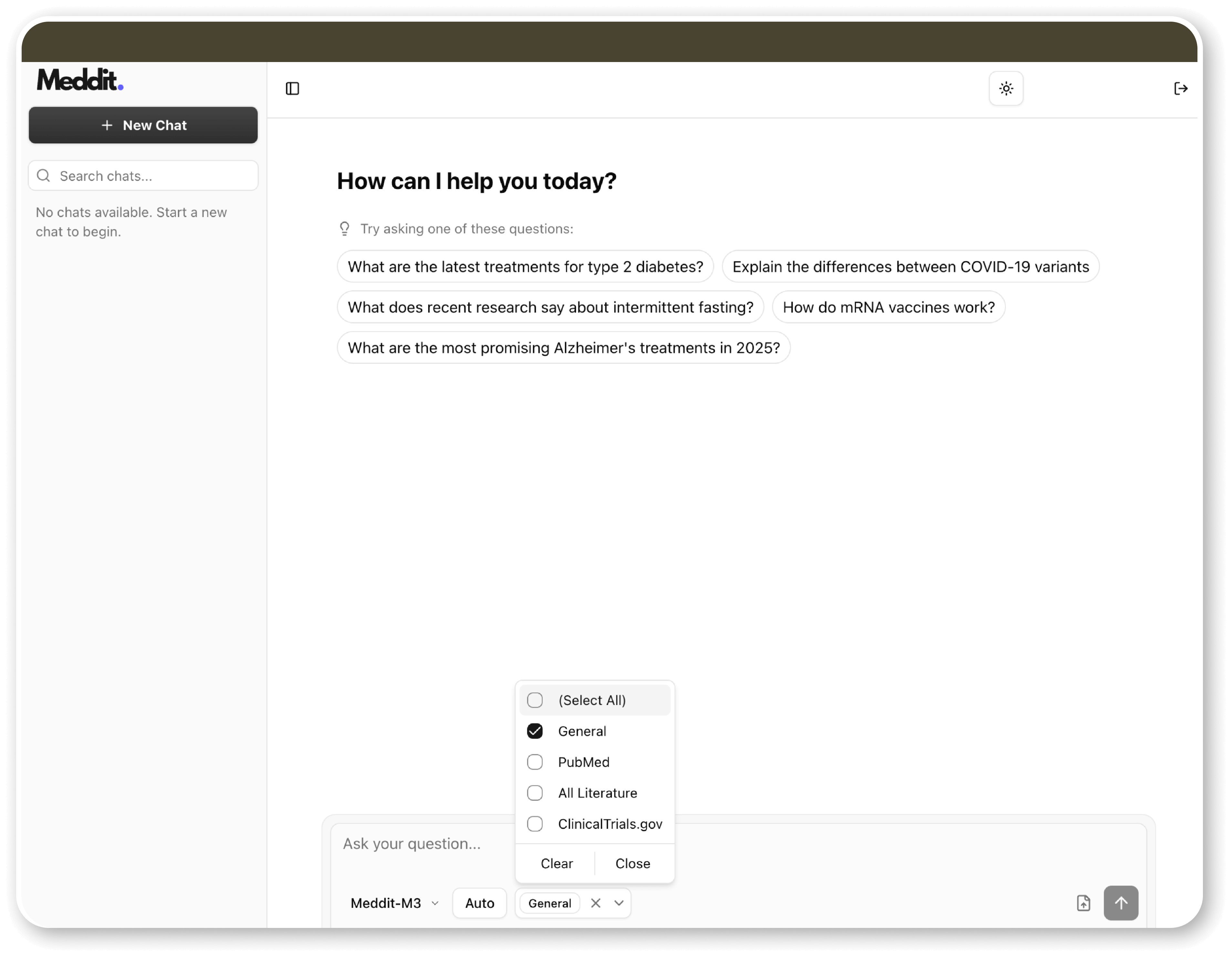
This ensures that every summary can be traced back to its origin, addressing the critical need for transparency and grounding.
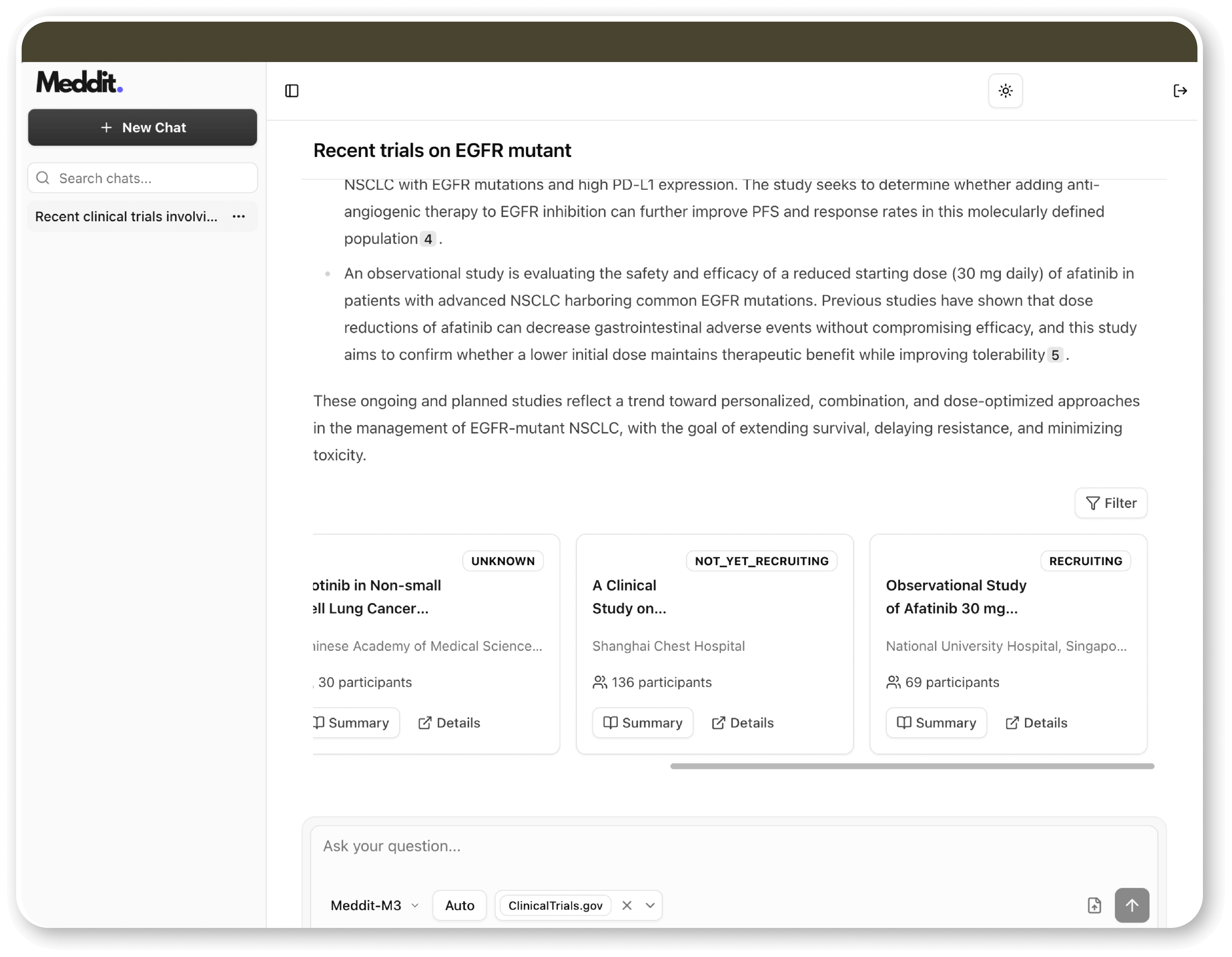
Beyond that, Meddit allows users to go deeper: you can engage in a focused chat with a single paper, asking follow-up questions and exploring its methodology, limitations, or results in more detail.
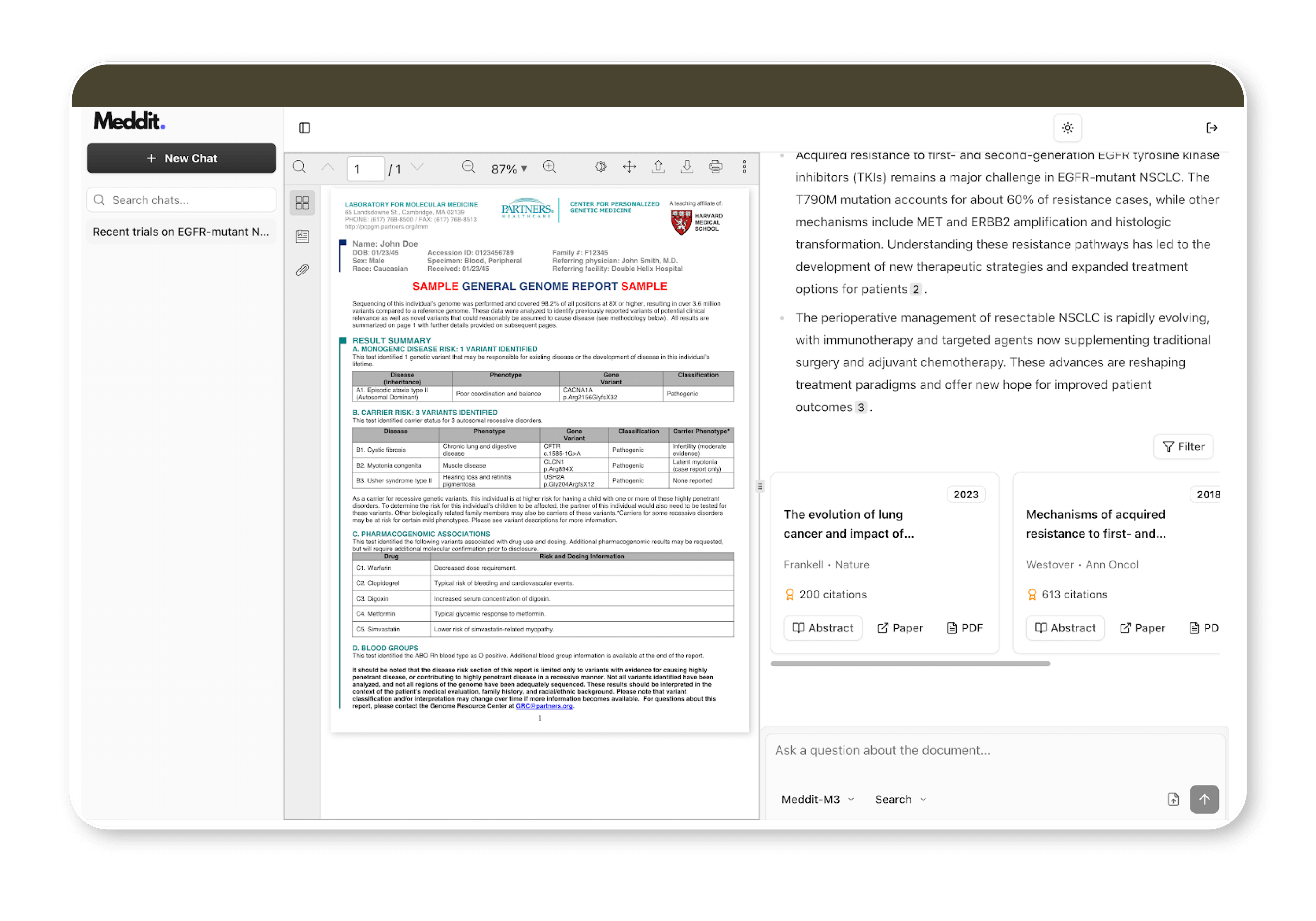
In doing so, our infrastructure aims to close the gap we discussed earlier. Our goal is to combine the efficiency of modern AI tools with the trustworthiness demanded by traditional evidence-based medicine.
Related Posts
- Bioinformatics
Personalized Medicine and Bioinformatics: The Future of Healthcare
The future of healthcare lies in the convergence of personalized medicine and bioinformatics, as these rapidly advancing fields are set to revolutionize diagnostics, treatment, and disease prevention. Personalized medicine refers to a medical model that utilizes genetic, environmental, and lifestyle factors to create tailored healthcare plans for individual patients. Bioinformatics, on the other hand, is an interdisciplinary field that combines biology, computer science, and statistics to analyze and interpret complex biological data.
Apr 2023
Abdullah Atia
- Bioinformatics
- Research
Reproducibility in Bioinformatics Research with Bionl
Reproducibility, the cornerstone of scientific integrity, is the ability to duplicate the results of a scientific experiment or study. In the realm of bioinformatics research, reproducibility takes on a heightened significance due to the complexity of experiments, specialized software, and large datasets involved. This article explores the challenges and solutions to achieving reproducibility in bioinformatics research, with a special focus on how Bionl.ai can facilitate this crucial aspect.
Nov 2023